
1·
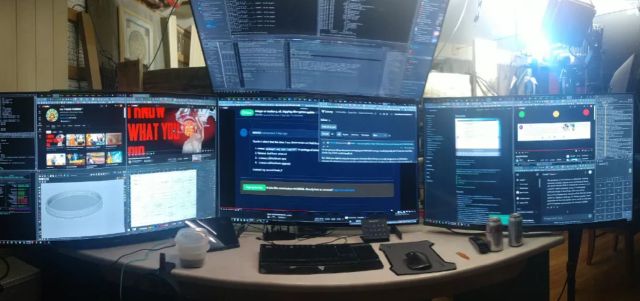
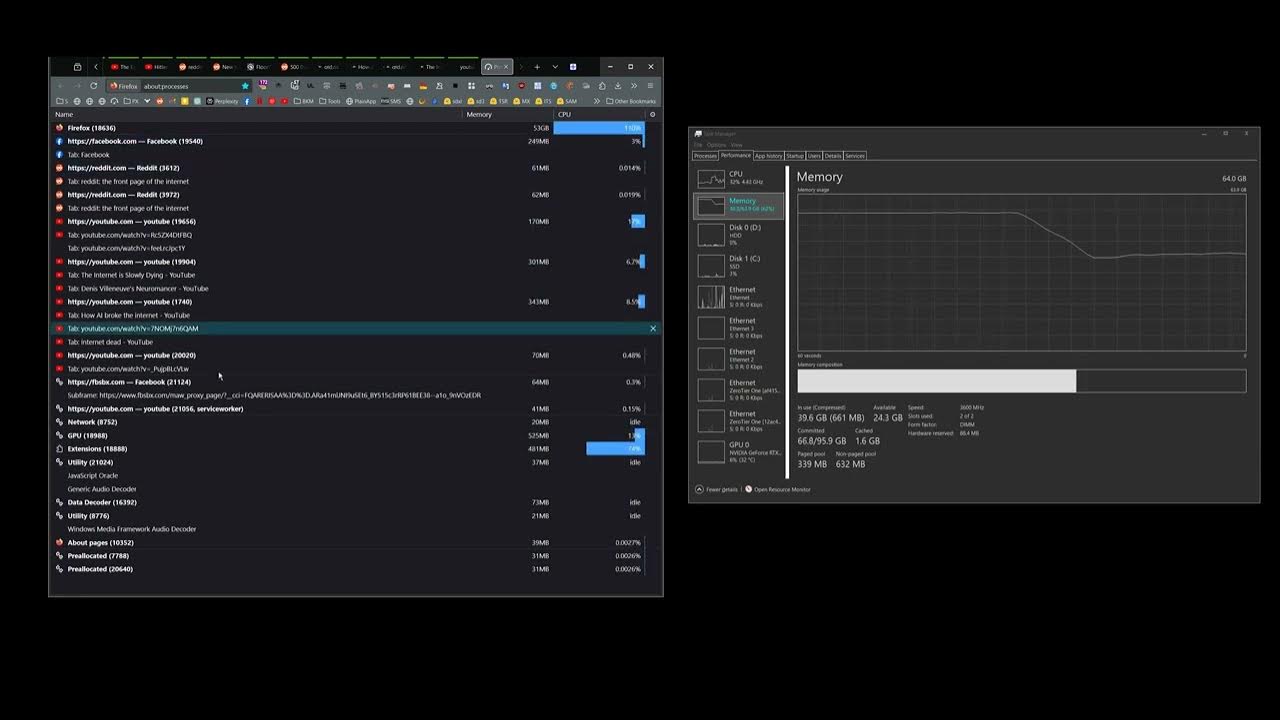
11 days agoI would prefer not to save and tags tabs 500 times per day. It’s easier to let them accumulate and handle them all in memory.
500 tab save and tag per day is too much labour, I would spend half my day just fiddling and sorting bookmarks !





{kind=link}
{kind=link}
Sounds great, I could use voidtool everything content: search